VLDB-2021 Building Enclave-Native Storage Engines for Practical Encrypted Databases
前言
文章动机
- 纯密码方案(
CryptDB、Arx)开销大,功能少 - TEE方案:
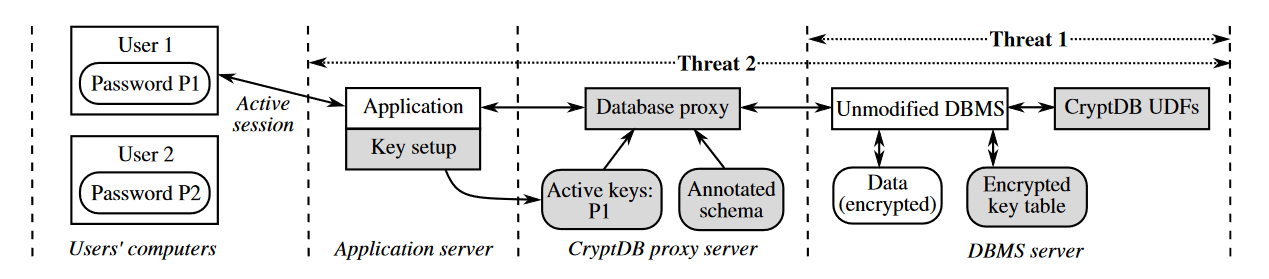
EnclaveDB、ObliDB安全性高但效率相对差Always-encrypted、StealthDB这类non-intrusive方案泄露的信息使其容易遭受攻击
贡献
- 提出多种在存储引擎上优化的设计,进而在安全、效率和功能性上做trade-off以达到enclave-native
- 将多种不同存储引擎设计融合一起(即本文的
Enclage),可以缓解ciphertext amplification - 设计合适的page size、用delta encryption来减少开销
- 巧妙设计index和table的执行逻辑以减少上下文切换
TEE-SGX
- 由于AMD SEV不支持
remote attestation,因此选择更为成熟的SGX
SGX面临的挑战
- enclave中有限的内存空间
- enclave与non-enclave之间的切换开销
- TCB(trusted computing base)的大小选择
- 侧信道攻击等(不属于做encrypted database人的范畴里,忽略)
Enclabve-based Encryption Scheme
数据模型
数据抽象
对于关系型数据模型,数据表中每个cell的值应当是使用达到IND-CPA的加密算法加密过的,例如AES-CBC模式。
其中对于每个表T,可以将其表述为含有n个列的数据,即T={C0,C1,C2…Cn-1},其中的C0是表中索引过的主键PK,因此加密后的表可以表示为[E(k), E(v1), …, E(vn-1)],其中的k为C0,vi即Ci;其API设计为如下:

索引和表格存储
本方案中选择将B+Tree和heap-file table store(表格存储)作为存储架构。当新的record需要被添加时:
- 首先将其追加在
heap-file table store,并为每个record分配一个rid(可以直接通过rid将record查询到) - 之后建立索引,key为索引中的项,value为对应record的
rid
因此上述过程相当于建立了一个关于rid的索引,通过rid来取得对应的record,因此对于table store TS它必须支持以下API:

其中,
rid在索引和table store之间的传输是可以加密也可以明文的,因此上述的OE相当于Optional Encryption,E即普通的Encryption
对于索引PI应当支持以下API:

威胁模型
在“文章动机”中提到,本文作者认为一些non-intrusive方案的安全性较低,因此本文提出的威胁模型并不是普通的honest-but-curious敌手,而是可以通过OS来访问数据库的敌手。
- 一方面该敌手可以查看服务器中内存、磁盘并且坚挺通信间的内容
- 另一方面可以通过主动攻击来篡改数据
- 但它不可以监听或破坏enclave中的计算、内容等,可以监听host和enclave之间的通信
此外,为了减少一些不必要的开销,本文中并未要求完全indistinguishability,对于元数据以及一些具有统计特征的属性(例如列名、table/index的大小、值的长度)并未保证其机密性,而是保证了一些方案中提出的_operational data confidentiality_来做权衡。
注:本文方案并为保护数据的完整性,但在具体实施过程中可根据不同方案的选择来达到不同的需求
Strawman:B+tree with Encrypted Keys
在先前Always-encrypted以及Arx中,设计了一种在B+树加密存储的结构,见下图:

该方案中的B+树与普通的B+树基本相同,只是灰色部分的块是加密处理过的,即此B+树将加密后的key作为索引,rid作为加密索引对应的值。对于上图中需要检索42,则从树根一直取key到enclave中一一比较,直到叶子节点即可。
这种设计的优势在于,当B+树的结构需要变化时(如split、merge),其不受enclave的影响,直接变化即可。此外,table store在取得rid之后也可离开enclave直接取得对应的record。
但这种方案也存在着十分明显的缺点:
- Frequent enclave interaction:对于索引中的每个key都要到enclave中进行比较
- High ciphertext overhead on computation and storage:对于大小比较小的密文不够友好,存在ciphertext amplification
- Severe information leakage:此种内部结构有泄漏,比如key的顺序和父子节点之间的关系,其安全性降低到了OPE级别;此外在索引查找过程中,其路径模式也遭到了泄漏,容易遭受leakage-abuse攻击
对于更多设计的探索
作者基于一直考虑的三个因素security、performance、functionality,分别从5个纬度来分析不同设计带来的不同结果。
- Encryption Granularity:
- item-level encryption:对每个item(索引的key或列中的值)进行加密,这种存储开销大且结构信息会泄漏,存在offline leakage;但灵活性高,一部分操作可以bypass enclave,例如node split
- page-level encryption:对每个page中的数据进行加密,泄漏信息少,但对其进行计算的任何操作都需要通过enclave,哪怕数据大小只有1bit
- Execution Logic in Enclave
将执行的逻辑放到enclave里面可以防止online数据被敌手监测,但逻辑实现的代码需要放到TCB中,TCB大小的选择便成为了一个需要考虑的问题。对于索引中key的比较是需要放入到enclave中执行的,而其余的一些操作例如table store的split等则可以在enclave外进行。
- key comparison in enclave:以key为单位在enclave中进行比较,优点和上面的item-level中的一样,但其查找过程中会泄漏搜索模式且大量调用ECall(调enclave的接口),安全性低且开销大
- index node access in enclave:以索引的node为单位比较,所以仅需调用一次ECall即可完成比较(node中含有key和指针),减少了泄漏
- none in enclave:不在enclave中比较,速度快但信息泄漏多
- data page access in enclave:以page单位进行比较,安全性高但性能中规中矩,所有操作需要在enclave中进行
- Memory Access Granularity
由于enclave可以访问进程的所有地址,包含host自己的地址以及host不允许访问的地址。正是因为这个特性,enclave如果访问host中的内存地址时,存在有泄漏host的访问模式的风险。
- item-level access:把需要的item读取到enclave中,速度快但会泄漏item的访问模式
- page-level access:将需要的整个page读取到enclave中,隐藏了可能真正需要访问的item,但性能一般
- Enclave Memory Usage
由于EPC容量有限,但enclave的性能又严重依赖于EPC,因此对于经常使用的数据可以在enclave中缓存起来
- minimun usage:无安全保护,性能低(无cache),无EPC开销
- fixed usage:隐藏一小部分常用items,性能一般,EPC开销小
- proportional usage:隐藏很多items,性能一般,EPC开销大
- unlimited usage:隐藏所有items,性能好,EPC开销大
- Record Identity Protection
在查询中,服务器发出的query可能会泄漏查询模式,因此应当做一定的保护措施。对于查询出的record和rid也应当被保护
- no action:泄漏
rid - rid encryption:隐藏
rid - ciphertext re-encryption:隐藏
rid和搜索模式
此外,上述5个纬度的考虑仅是单方面的考虑,而对于一个成熟的系统来说,应当从整体角度出发进行对比。因此对于一个系统的安全性来说,决定其安全性的往往是安全性最低的某个点,所以将上述考虑结合起来才是最后的目标所在。
Enclage
综合上面提到过的设计思路,这里引出本文设计的enclave-native加密存储引擎,它由Enclage Index和Enclage Store组成。
Enclage的设计
正如Enclage分成的两部分的名称所示,一部分为像B+树一样的索引,另一部分为像heap-file table store的存储。在Enclage中,加密设计上索引和存储都选择了page-level encryption。
- 针对索引选择使用
index node access作为执行逻辑减少ECall次数并采用page-level access作为数据粒度读取至enclave内存中;另外本文选择将EPC大部分空间分配给索引以提高检索效率,并以fixed EPC usage作为内存分配 - 针对存储本方案选择使用
data page access作为执行逻辑,为了给索引节省EPC因此选择item-level access读取数据,并使用delta decryption protocol减少加密开销,最后默认使用rid encryption和ciphertext re-encryption保护rid安全。
Enclage Index
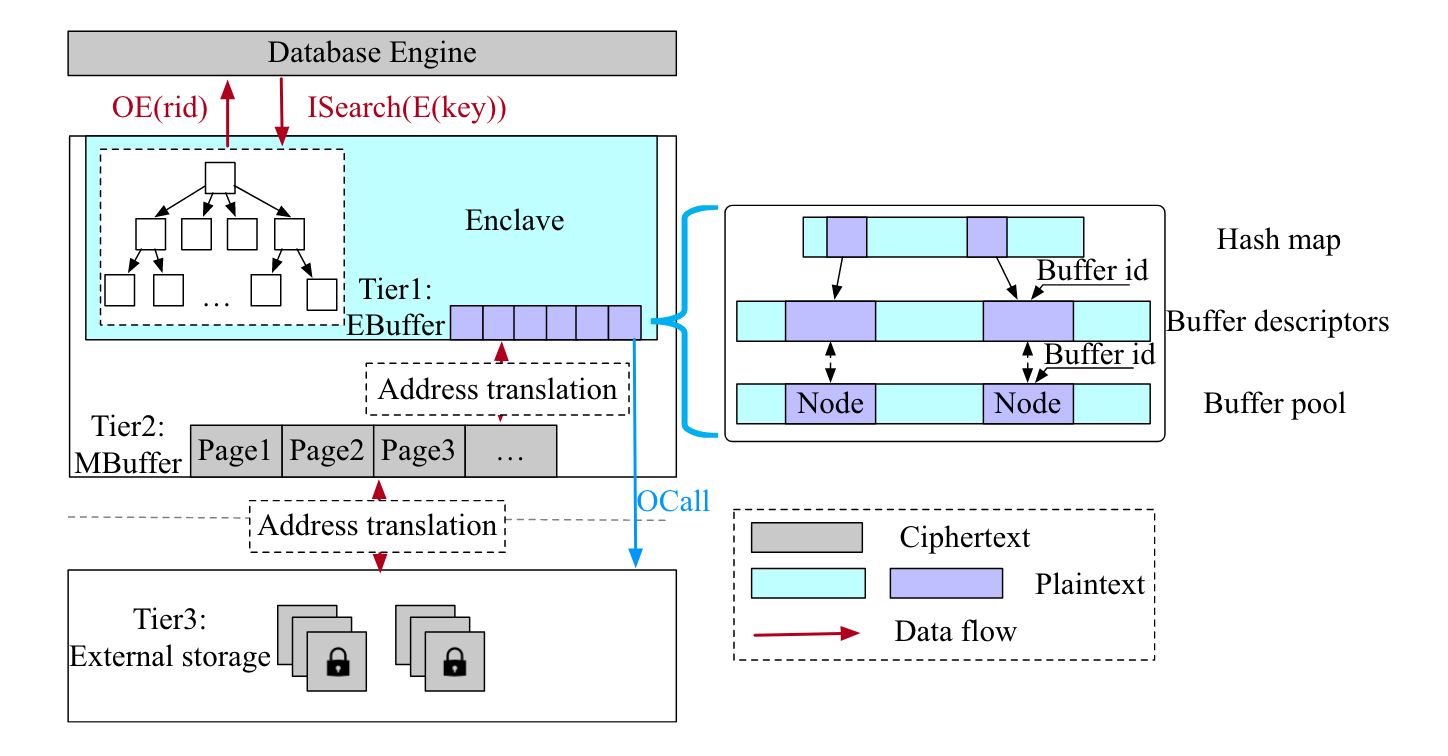
索引使用三层存储结构,具体结构见下图:
- EBuffer:负责enclave memory和unprotected host memory之间的数据转移,其中的page明文存放
- MBuffer:负责host memory和external storage之间的数据转移,其中的page密文存放
- external storage:存放外部数据

对于上面的EBuffer和和MBuffer,其内部也是一个三层结构(见上图右侧):
- Buffer pool:一个存放entry slots的数组,其中每个entry slot可以为一个index node也可以为一个page,支持随机存取
- Buffer descriptors:与Buffer pool位置一一对应,存放对应entry的元数据
- Hash map:通过nodeID或pageID快速定位entry的map,使用MurmurHash作为哈希算法,并用外链entry解决冲突
注:
- EBuffer和MBuffer除了内部entry加密与否外没有区别
- 当EBuffer中满后需要用LRU做驱逐时,可以根据情况来延迟刷脏
- Buffer地址之间的转换根据实际情况计算(例如首址+偏移量等)
- 其中的node需要access时,先判断EBuffer,没有则从MBuffer取,再没有则调用OCall从磁盘取,步骤与常见的Buffer pool类似
Index优化
- 减少EPC page的交换:采用将大部分EPC空间留给EBuffer,尽量减少其他组件EPC空间的策略
- 减少加解密的开销:node大小的选择会直接影响到EBuffer的集中率,本文中得出的最佳node size是1KB(证明略)
- 避免不必要的OCalls:当所需要索取的entry不在EBuffer和MBuffer是会调用OCall,但实际上存在更好的解决方案。由于enclave可以直接访问host memory,因此所有已在host memory的page都可以直接被enclave访问而无需OCall(所以如果host memory够大则可以减少许多OCall?)
Enclage Store
存储是类似于heap-file table store的结构,每次有record追加后会分配给其一个unique rid,随后该rid会被添加到索引中(该rid可用来定位对应record的位置)。
此外,由于record的内容需要加密后再放入Buffer中。因此record的内容首先会被放到一个放在enclave memory中的active data page中,当page满后才会将其加密并放到MBuffer中。
data locality的定义使得其在Store中比Index少,因此没有必要维护一个关于存储的cache。另外由于数据是page-level encryption,每次取回数据都是一个page,在这种粒度上的解密是开销比较大的,因此引出了delta decryption protocol来解决此问题。
Delta Decryption Protocol
其本质是一个建立在AES-CTR模式下的协议,作用是在一个大密文下单独为某个小块解密。为了理解这一协议,首先需要了解AES-CTR模式的运作方式:

在该模式下的加密步骤为:
- 根据Nonce和Counter拼接得到对应的IV
- 将得到的IV在对应的key下加密
- 加密后的IV与明文亦或即得到密文
解密步骤是加密步骤的逆过程。
而本文中的Delta Decryption Protocol中的Nonce是保存在Buffer descriptor中的元数据,而Counter可以根据不同的[Offset/16]计算出来,因此解密某个record的密文只需得到元数据而计算Counter即可解密出密文,而无需解密整个page。
Scalability & Integrity
- Scalability:在enclave和enclave外是相同的,其并发控制是没有区别的,因此外面啥样里面也啥样
- Integrity:可以采用一些方案中提出的Merkel B-Tree来防止篡改和重放攻击
Implementation
在前面索引和存储的部分中已经提到过一部分实现细节,这里仅介绍一些主要的数据结构
- Cipher:需要包含IV、MAC来解密用、密文长度、index node或者一些data page
- Index node:包含nodeID,相邻节点间指针,类型(leaf or internal)
- MBuffer entry:pageID、dirty标志位、number of components accessing page(pin_count)等
- EBuffer entry:与MBuffer相似,除了是明文